How Deep Learning is changing machine learning AI in EEG data processing
Electroencephalography (EEG) offers a powerful window into the brain, capturing signals associated with cognition, behaviour, and emotion. Beyond its use in neuroscience research, EEG technology is finding growing applications in healthcare, emotional monitoring, and even human performance enhancement.
However, interpreting EEG data remains a complex challenge. The signals are often noisy, individualized, and can fluctuate significantly even within the same person over time. Traditional analytical methods struggle to handle this variability.
That is where artificial intelligence—and more specifically, deep learning—comes into play. In this article, we examine how AI and machine learning are currently utilized to process EEG data and how deep learning is paving the way for a new era in brain signal analysis. Emerging neural networks are enhancing accuracy, automating feature extraction, and facilitating real-time interpretation, thereby making EEG more accessible and impactful across various industries.
Why Machine Learning Is Essential for EEG Data Analysis
EEG captures the brain's electrical activity through electrodes placed on the scalp. While it offers valuable insights into neural function, the data generated is notoriously challenging to work with. The signals are often noisy, filled with artefacts, and unlike more intuitive data formats, such as images or charts, they are not easily interpretable. Extracting meaningful patterns from EEG recordings requires specialized expertise.
Even seasoned neurologists, neuroscientists, and biomedical engineers spend years learning how to interpret these complex signals. Even for experts, raw EEG data must undergo significant preprocessing—such as temporal and spatial filtering and artifact removal—before it can be meaningfully analyzed. Only then can specialists visually examine the data to identify anomalies, such as epileptic episodes, monitor sleep phases, or explore group-level neural responses.
However, visual inspection is time-consuming, labour-intensive, and difficult to scale. It is also not suited for real-time applications, such as brain-computer interfaces (BCIs). That is where machine learning becomes indispensable.
Machine learning algorithms can automate EEG data analysis, improving both speed and accuracy. These models can detect subtle patterns that might be missed by the human eye and can adapt to inter-individual variability. BCI systems—like spellers or brain-controlled devices—rely heavily on machine learning pipelines to decode brain activity and translate it into actionable outputs. As EEG applications continue to expand, AI-driven approaches are key to unlocking their full potential.
Before Deep Learning: Signal Processing, Feature Extraction, and Traditional Machine Learning in EEG
Before the rise of deep learning, EEG analysis followed a well-established pipeline that relied heavily on classical signal processing and conventional machine learning techniques. These approaches aimed to improve the signal-to-noise ratio, manage artefacts, extract relevant features, and ultimately decode or interpret brain activity.
This standard workflow typically involved multiple sequential steps: filtering the raw signals to isolate meaningful frequency bands, applying artifact rejection methods, and then extracting handcrafted features—such as power spectral density (PSD), event-related potentials (ERPs), or spatial patterns. These features were then fed into traditional classifiers like support vector machines (SVMs), linear discriminant analysis (LDA), or random forests to perform tasks such as mental state classification or anomaly detection.
Figure 1 shows the most common pipeline when processing EEG.
 Figure 1: The three important steps when processing EEG: 1) Pre-processing deals with noise, artefacts, and SNR enhancement; 2) feature extraction further processes the signal to create meaningful descriptors for the decoding task at hand; and 3) decoding uses classification/regression models to transform the EEG features into high-level signals such as letters in a speller, directions of motion, affective or cognitive states or clinical markers.
Figure 1: The three important steps when processing EEG: 1) Pre-processing deals with noise, artefacts, and SNR enhancement; 2) feature extraction further processes the signal to create meaningful descriptors for the decoding task at hand; and 3) decoding uses classification/regression models to transform the EEG features into high-level signals such as letters in a speller, directions of motion, affective or cognitive states or clinical markers.
Preprocessing EEG Signals: From Raw Data to Meaningful Patterns
From a computational perspective, EEG signals are essentially multivariate discrete-time series. Each time point corresponds to a simultaneous recording across multiple EEG channels, and the number of electrodes used defines the dimensionality of the data. The length of the signal depends on the duration of the recording and the sampling rate—for example, 256 Hz means 256 data points are captured per second, per channel.
However, raw EEG data is rarely used directly for analysis. These signals often contain undesirable elements such as DC offsets, slow drifts, electromagnetic interference, and various physiological or environmental artifacts. Therefore, the first step in EEG analysis is signal preprocessing—a critical stage where noise is reduced, artefacts are filtered out, and the underlying brain activity is isolated.
This task is far from trivial. The challenge of separating meaningful neural signals from background noise has led to the development of an entire field of research focused on artifact removal and signal cleaning.
Once the signal has been preprocessed, researchers can begin to extract the neural signatures associated with cognitive, emotional, or behavioral processes. Often, these signatures are concentrated within specific frequency bands. For example, the P300 evoked response is typically found within the theta range (4–7 Hz), while sensorimotor rhythms, such as the mu wave, are located between 8 and 15 Hz.
To focus on these patterns, frequency-based filtering is commonly applied. Low-pass, high-pass, or band-pass filters help isolate relevant frequency components while discarding irrelevant or noisy ones. Figure 2 illustrates the typical EEG frequency spectrum, highlighting the bands most frequently analyzed in neuroscience and brain-computer interface (BCI) research.
 Figure 2: Left: EEG spectrum for two different conditions: focused vs. distracted. Based on it, one may select the frequency range shaded in Grey to distinguish these two conditions. Right: EEG activity filtered on the most common bands. The Gamma Band [30--140Hz] also shows correlated activity with cognitive processes and shows alteration for cognitive disorders.
Figure 2: Left: EEG spectrum for two different conditions: focused vs. distracted. Based on it, one may select the frequency range shaded in Grey to distinguish these two conditions. Right: EEG activity filtered on the most common bands. The Gamma Band [30--140Hz] also shows correlated activity with cognitive processes and shows alteration for cognitive disorders.
EEG Signal Feature Extraction
Once EEG data is preprocessed, the next step is to extract features that reveal brain activity patterns. Before deep learning, this was done using handcrafted techniques tailored to specific applications, ranging from basic statistical features to more advanced spatial filters.
Generic methods, such as Principal Component Analysis (PCA) and Independent Component Analysis (ICA), were widely used. In contrast, EEG-specific techniques, including Common Spatial Patterns (CSP), (Blankertz, 2007), focused on power differences, while X-Dawn (Rivet, 2009) specialized in temporal cue enhancement, especially for evoked potentials.
Feature selection was task-dependent, distinguishing attention levels, classifying mental states (e.g., spellers), predicting behaviour (e.g., by anticipating motion in neurorehabilitation), or detecting anomalies in a normative database (e.g. , QEEG or seizures). More recent techniques—such as Riemannian geometry-based classifiers, filter banks, and adaptive models—have improved robustness in handling EEG’s complexity.
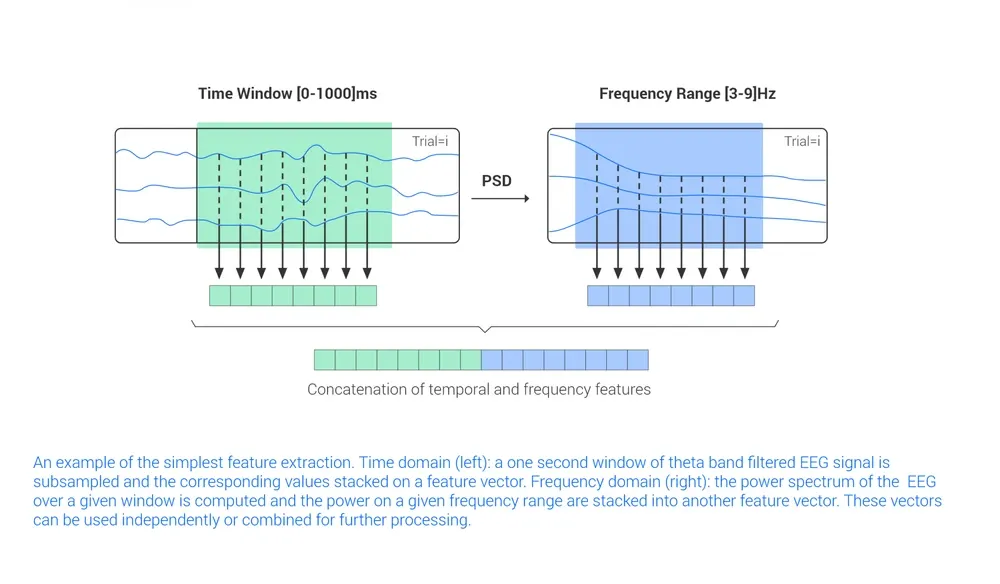
Figure 3. An example of the simplest feature extraction. Time domain (left): a one second window of theta band filtered EEG signal is subsampled and the corresponding values stacked on a feature vector. Frequency domain (right): the power spectrum of the EEG over a given window is computed and the power on a given frequency range is stacked into another feature vector. These vectors can be used independently or combined for further processing.
The extracted features are usually tailored to the specific application, such as finding differences between experimental conditions (e.g. levels of attention, responses to mismatched actions), distinguishing between a group of predefined classes (e.g. a speller), predicting behavior (e.g. by anticipating motion in neurorehabilitation), finding anomalies with respect to a normative database (e.g. QEEG or seizures). Current state-of-the-art techniques include Riemannian geometry-based classifiers, filter banks, and adaptive classifiers, used to handle, with varying levels of success, the challenges of EEG data (Perronnet, 2016, Lotte 2018).
EEG Data Decoding: From Features to Insightful Predictions
Once relevant features have been extracted from EEG signals, the next step is to decode the brain activity, automatically translating neural patterns into meaningful information. The most widely used approach is supervised learning, which relies on labelled data to train models that can classify or predict cognitive or behavioural states.
In this paradigm, a model is trained using a training dataset composed of examples with known outcomes. The goal is to learn a mapping from EEG features to target outputs, such as mental commands or emotional states. The two main decoding strategies are:
- Classification, which assigns EEG segments to predefined categories (e.g., attention vs. rest).
- Regression, which maps EEG features to continuous outputs (e.g., hand movement trajectory).
Common algorithms include:
- Linear methods like LDA and Multiple Linear Regression;
- Support Vector Machines (SVM) and other kernel-based models;
- Random forests;
- Neural networks (for deep learning, see Section 4);
- Alternatively, hybrid models combine several of the above.
Unlike image or text data, EEG is non-stationary and highly individual. This introduces two key challenges:
- EEG features for one person may change over time, even within the same session.
- Features that work for one participant may not generalise to others.
In other words, the feature distribution shifts over time and between individuals. This makes model generalisation difficult, as it requires frequent retraining with new data. Initially, EEG decoders were trained separately for each participant and session, making real-world deployment labour-intensive due to the need for constant calibration.
To address this, newer techniques aim to minimise calibration and build robust, cross-participant models that can adapt to different users and conditions with little retraining (Lopéz-Larraz, 2018).
Most decoding models assume that the timing of relevant EEG activity is known, for example, during a controlled task like an EEG speller. However, in many practical neurotech and BCI applications, the timing is unknown or variable. Examples include detecting an epileptic seizure at home or identifying the intention to move a limb during a neurorehabilitation session. These scenarios require asynchronous decoding, where the system must not only recognise relevant patterns but also discriminate them from continuous background EEG.
A standard solution is the sliding window approach, where the EEG signal is segmented into overlapping windows and analyzed continuously. During training, “rest” periods are labelled using baseline data, and event onsets are marked using auxiliary signals like EMG or manual input. The same supervised algorithms can then be applied to build a model that provides real-time, continuous decoding.
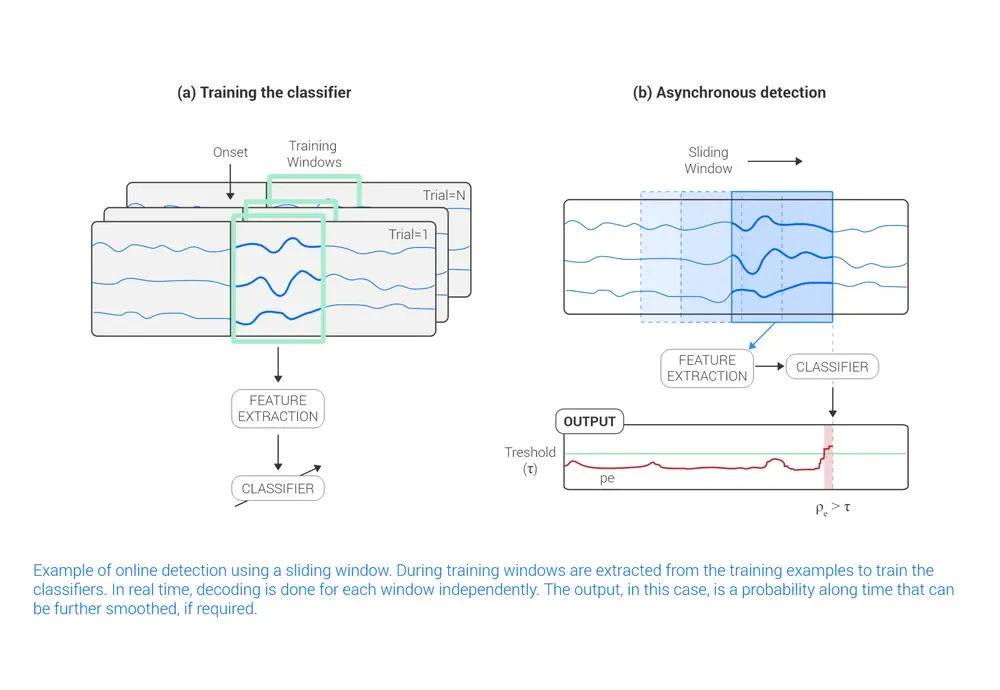
Figure 4: Example of online detection using a sliding window. During training, windows are extracted from the training examples to train the classifiers. In real-time, decoding is done for each window independently. The output, in this case, is a probability along time that can be further smoothed, if required.
Deep-Learning for EEG
Deep learning has radically changed machine learning in many domains (e.g. computer vision, speech, reinforcement learning, etc.) by providing general purpose and flexible models that can work with raw data and learn the appropriate transformations for a problem at hand. These models can use large amounts of EEG data to directly learn features and capture the data structure in an efficient way that can be then transferred and/or adapted to different tasks. This end-to-end learning ability fits perfectly with the requirements of EEG analysis, where multiple interdependent processes are key and, until recently, were carefully designed for each different purpose.
Deep learning EEG challenges
EEG data has its own challenges.
- First, data collection is still expensive, time-consuming, and restricted to a small number of teams working mainly in research laboratories. Medical data is not usually available due to personal data regulation, and data collected from companies is also private due to the same reason. Consequently, the corpus of data is by no means close in size to other domains such as computer vision or speech recognition. Many public EEG datasets only have a small number of participants, the order of tens (see Google Dataset search for EEG datasets and the BNCI database for BCI datasets). Some fields such as sleep and epilepsy do have public larger datasets with thousands of participants. For epilepsy, the Temple University Hospital dataset has over 23,000 sessions from over 13,500 patients, for a total of over 1.8 years of recording (Obeid, 2016). In sleep, the Massachusetts General Hospital Sleep Laboratory has over 10,000 participants with 80,000 hours of recordings, which is over 9 years.
- Second, the amount of information is limited due to a low signal to noise ratio and depends heavily on the data collection protocol. This limits, even more, the amount of available data and makes the transfer between protocols and participants more difficult.
- Third, models developed for images and speech have been studied for many years and, although technically generic, they are not necessarily the most appropriate ones for EEG. This also includes many good strategies used for training the models that cannot be so efficiently implemented in EEG, such as data augmentation techniques for images (Hartmann, 2018).
How can deep learning be used for EEG decoding?
These challenges have not stopped researchers and practitioners from using deep learning, and the last 10 years have seen a fast increase of results across all the fields related to EEG data. There has been an increasing interest in using this type of technique. A very interesting review over more than 100 papers sheds light on the current state of the art. Figure 5 shows how the main fields of application of EEG data analysis have tried deep learning and what deep models are the most common. There is still no clear dominant architecture. Many of those applied to EEG have been directly borrowed from previous applications such as computer vision. Therefore, convolutional neural networks (CNNs) are the most common architecture, while autoencoders and recurrent networks are also used often.
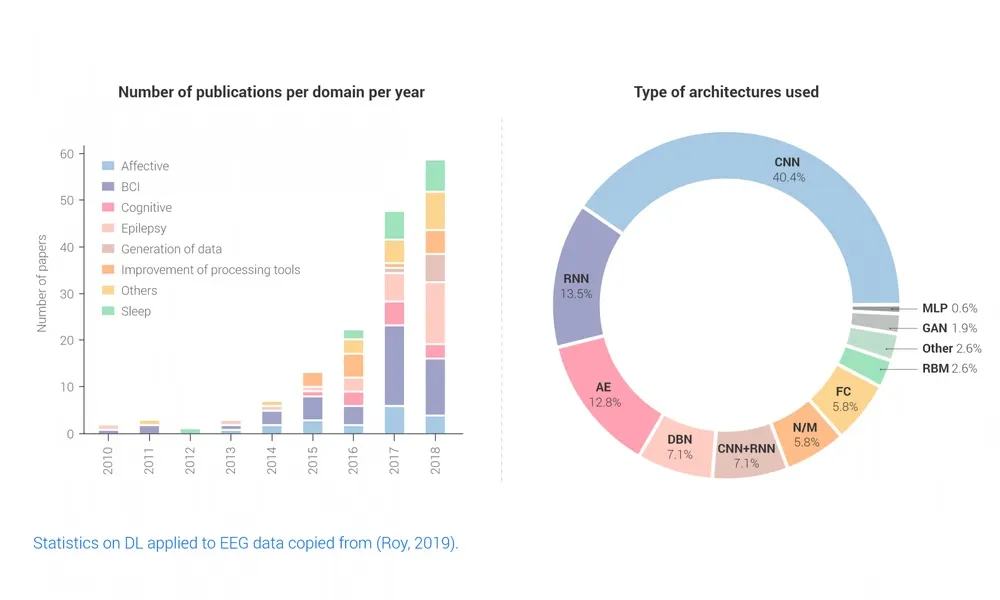
Figure 5: Statistics on DL applied to EEG data copied from (Roy, 2019): Number of publications per domain per year (left) and type of architectures used (right).
In most cases, the deep learning methods perform feature extraction and decoding simultaneously (see Figure 1) and they use the same supervised approach described in Section 2. In many cases, the pre-processing is simplified, for example, by computing power features or segmenting the input data. Interestingly, some deep models have shown end-to-end decoding performance, improving previous methods while dealing directly with common EEG issues such as eye motions (eye-opening and closing, blinking, etc.), artifacts, or background EEG.
What are the results of Deep Learning EEG decoding? And, how do results compare to previous methods?
The authors of the meta-review in Roy (2019) have computed the median improvement in accuracy to be around 5.4% consistently across all domains shown in Fig. 6. Although they also point out some reproducibility concerns, the results show that, despite the challenges mentioned above, Deep Learning improves decoding results - in many cases, with minimal or no pre-processing. One interesting consequence of using data-hungry deep learning techniques is that the standard participant/session-specific setup has been substituted for a more ecological one where all sessions and participants contribute for decoders. To give a more detailed view, we highlight results in three different applications that are relevant for understanding the current state of the art:
- Mental task decoding: Perhaps the most successful deep learning models are Convolutional Neural Networks. In this first example, we will look at how they can be used to decode end-to-end mental tasks from EEG. End-to-end decoding exploits deep architectures by learning maps directly from the raw data and obtaining high-level representations, in this case, the mental imagination of the user. Convolutional networks were designed in computer vision and they can be seen as shift-invariant spatial filters over the image. They learn local features that are then used to create higher-level features in deeper layers of the neural network.
This same idea can be used to create time and frequency filters that automatically learn features from the raw EEG, and then learn more complex features from there. Figure 6 shows the ConvNet architecture proposed in (Schirrmeister, 2017). The results show that an end-to-end mapping can perform as well as filter bank common spatial patterns (FBCSP), the current state of the art method developed specifically for motor imagery (Ang et al., 2008). While FBCSP is designed to use spectral power modulations, the features used by ConvNets are not fixed a priori. For those interested in detailed technical implementation aspects, (Schirrmeister, 2017) provides a deep insight on how recent developments in regularization and normalization can make a big difference when training your model.
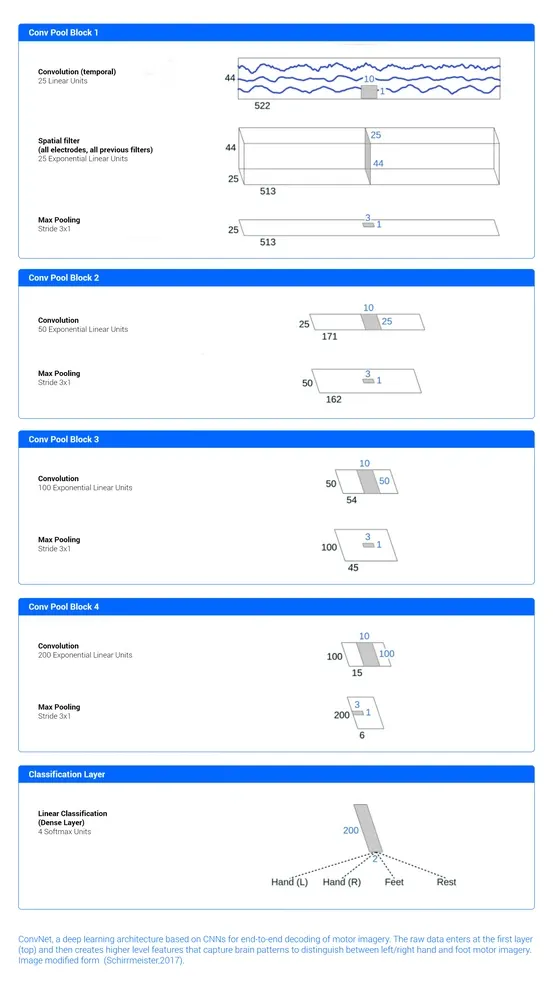
Figure 6: ConvNet, a deep learning architecture based on CNNs for end-to-end decoding of motor imagery. The raw data enters at the first layer (top) and then creates higher-level features that capture brain patterns to distinguish between left/right hand and foot motor imagery. Image borrowed from (Schirrmeister, 2017).
- Sleep EEG decoding: The SLEEPNET model (Biswal, 2017) has been trained and evaluated in the largest sleep physiology database assembled to date, consisting of polysomnography (PSG) recordings from over 10,000 patients from the Massachusetts General Hospital (MGH) Sleep Laboratory. SLEEPNET implements a recurrent network and achieves human-level annotation performance on an independent test set of 1,000 patients, with an average accuracy of 85.76% and algorithm-expert inter-rater agreement (IRA) of κ= 79.46%, comparable to expert-expert inter-rater agreement. This represents a 10% increase in accuracy over non deep learning methods. For those interested, Cohen’s kappa κ is used in sleep studies to measure agreement between different annotations of the sleep done by medical doctors, which have an inter-rate agreement around 65-75%. Figure 7 below shows an example of annotated sleep EEG and predicted states.
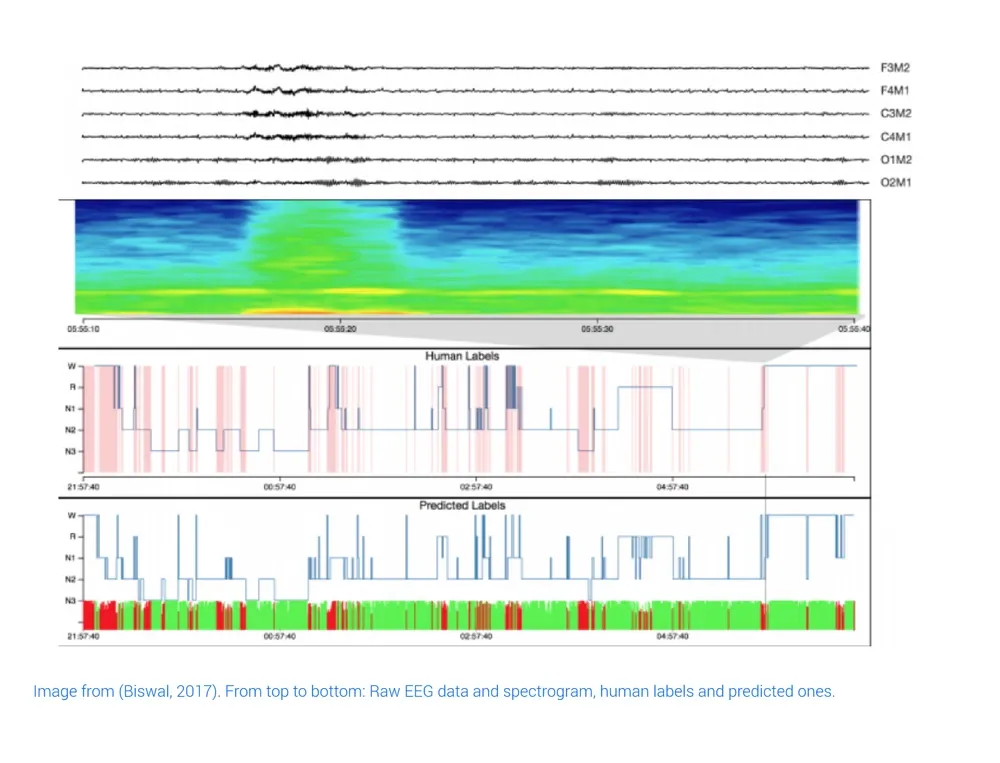
Figure 7: Image from (Biswal, 2017). From top to bottom: Raw EEG data and spectrogram, human labels, and predicted ones.
- Decoding affective states. One of the most common databases for decoding affective states is DEAP (Koelstra, 2011). It consists of 40 minute EEG and other biosensors recordings while watching music videos for a total of 32 subjects (see Figure 8 for some examples). It has been widely used to evaluate deep learning techniques with different architectures from autoencoders, CNNS, recurrent networks, and hybrid approaches, and with different preprocessing pipelines by varying the number of channels and including raw data or simple features (e.g. PSD). Current results obtain accuracies between 70 and 80% (see Craik, 2019) for a complete review and (Li, 2020) for recent results and comparisons with non deep learning approaches).
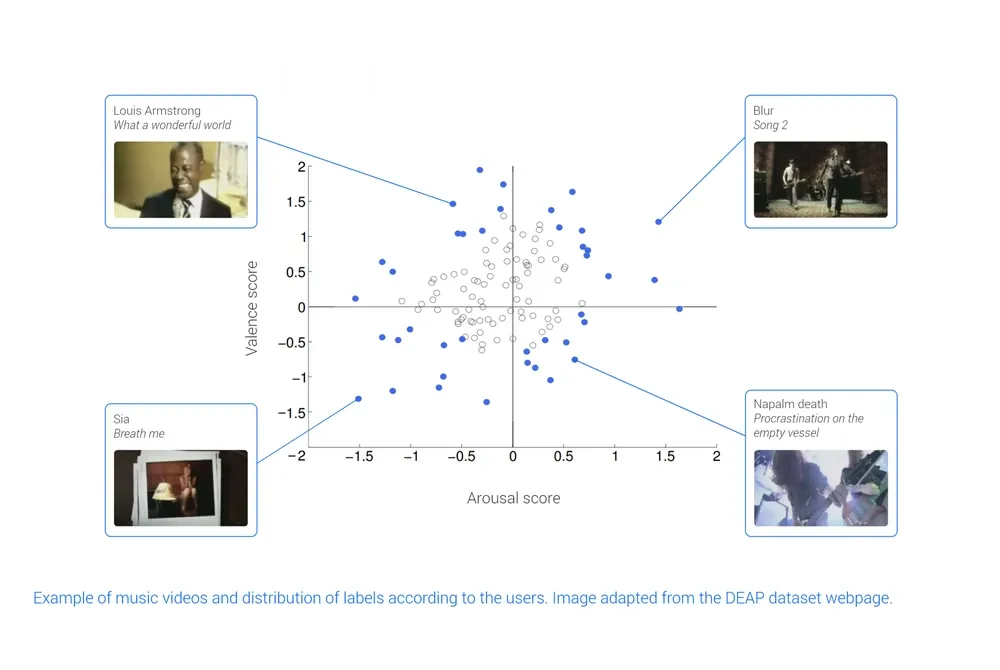
Figure 8: Example of music videos and distribution of labels according to the users. Image copied from the DEAP dataset webpage.
- Epilepsy detection: The last method is about detecting patterns of clinical interest in brain activity that might be useful in diagnosing brain disorders, in particular, brain patterns related to epilepsy. In contrast with the previous examples, the system described in (Golmohammadi, 2019) uses a hybrid approach (see Figure 9) that combines deep learning with dynamic hidden Markov models and statistical language modeling techniques to capture expert knowledge and include it in the system. In addition to this, it has dedicated feature extraction tailored to detect three brain patterns that occur during epileptic episodes (spike and sharp waves, periodic lateralized discharges, and generalized periodic discharges) and three patterns to model artefacts, eye movements, and background noise. The model was trained and evaluated in the TUH EEG Corpus (Obeid, 2016), which is the largest publicly available corpus of clinical EEG recordings in the world. It achieved a sensitivity above 90% while maintaining a false alarm rate below 5%, which may be enough for clinical practice.
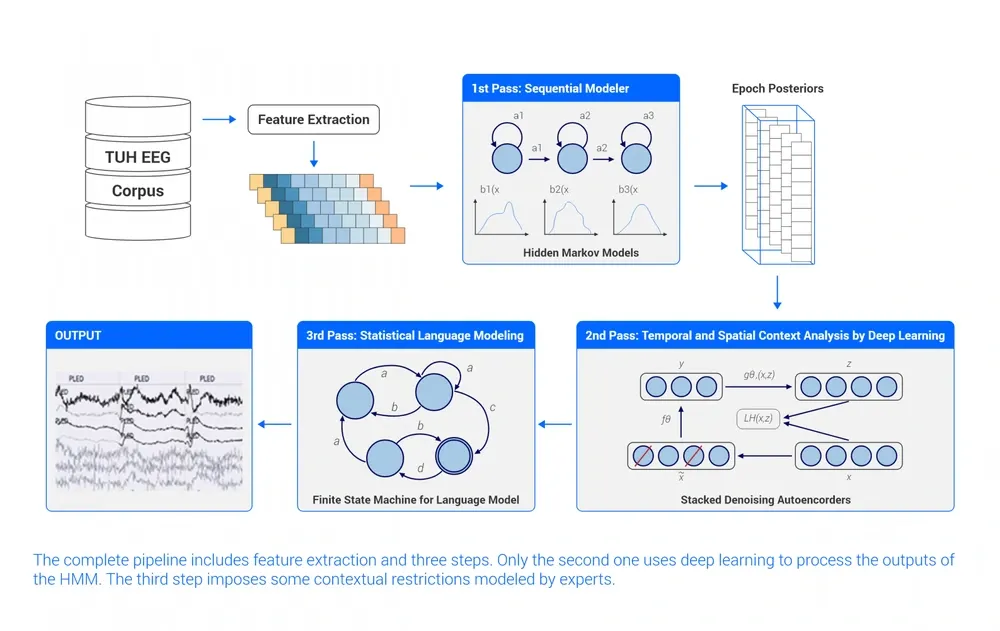
Figure 9: The complete pipeline includes feature extraction and three steps. Only the second one uses deep learning to process the outputs of the HMM. The third step imposes some contextual restrictions modeled by experts.
The previous examples show that deep learning techniques are now present in all EEG decoding applications and represent the current state of the art. There are still many open questions, such as which models work best, and whether EEG- specific models and algorithms are needed
For those interested in the technical details of how the different networks have been used with EEG, we recommend consulting some very complete reviews (Roy, 2019; Craik, 2019) that provide references to the appropriate works. Most of the results have been obtained using public datasets and code is available in the corresponding repositories (see for instance, the braindecod github for a complete deep learning decoding using CNN networks (Schirrmeister,2017)).
A final note of caution
Beware of the hype! The increased number of EEG experiments or studies claiming better results with deep learning have not been free of controversy. Reproducibility and, when possible, comparison against well based established baselines are a must, and their lack should be treated carefully when evaluating any claims. Interestingly, Roy (2019) points out that only 7% of the reported results provide both the software (19%) and the datasets (54%) required to evaluate and replicate the method. Sometimes there are sensitive reasons for not providing source and datasets, such as privacy in medical records, or the need to exploit the dataset or the code for your own research before making it public. Nevertheless, nowadays these good practices are becoming more common and, in some cases, are required to publish the data. They are always a good indicator of the quality of the work and a good starting point for your own projects.
References
- Perronnet, L., Lécuyer, A., Lotte, F., Clerc, M., & Barillot, C. (2016). Brain-Computer Interfaces 1: Foundations and Methods. https://www.wiley.com/enus/Brain+Computer+Interfaces+1%3A+Methods+and+Perspectives-p-9781848218260
- Lotte, F., Bougrain, L., Cichocki, A., Clerc, M., Congedo, M., Rakotomamonjy, A., & Yger, F. (2018). A review of classification algorithms for EEG-based brain–computer interfaces: a 10 year update. Journal of neural engineering, 15(3), 031005. https://doi.org/10.1088/1741-2552/aab2f2
- Rivet, B., Souloumiac, A., Attina, V., & Gibert, G. (2009). xDAWN algorithm to enhance evoked potentials: application to brain–computer interface. IEEE Transactions on Biomedical Engineering, 56(8), 2035-2043. https://doi.org/10.1109/TBME.2009.2012869
- Blankertz, B., Tomioka, R., Lemm, S., Kawanabe, M., & Muller, K. R. (2007). Optimizing spatial filters for robust EEG single-trial analysis. IEEE Signal processing magazine, 25(1), 41-56. https://doi.org/10.1109/MSP.2008.4408441
- Ang, K. K., Chin, Z. Y., Zhang, H., & Guan, C. (2008, June). Filter bank common spatial pattern (FBCSP) in brain-computer interface. In 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence) (pp. 2390-2397). IEEE.
- Roy, Y., Banville, H., Albuquerque, I., Gramfort, A., Falk, T. H., & Faubert, J. (2019). Deep learning-based electroencephalography analysis: a systematic review. Journal of neural engineering, 16(5), 051001. https://doi.org/10.1088/1741-2552/ab260c
- Craik, A., He, Y., & Contreras-Vidal, J. L. (2019). Deep learning for electroencephalogram (EEG) classification tasks: a review. Journal of neural engineering, 16(3), 031001. https://doi.org/10.1088/1741-2552/ab0ab5
- Schirrmeister, R. T., Springenberg, J. T., Fiederer, L. D. J., Glasstetter, M., Eggensperger, K., Tangermann, M., ... & Ball, T. (2017). Deep learning with convolutional neural networks for EEG decoding and visualization. Human brain mapping, 38(11), 5391-5420. https://doi.org/10.1002/hbm.23730
- Golmohammadi, M., Harati Nejad Torbati, A. H., Lopez de Diego, S., Obeid, I., & Picone, J. (2019). Automatic analysis of EEGs using big data and hybrid deep learning architectures. Frontiers in human neuroscience, 13, 76. https://doi.org/10.3389/fnhum.2019.00076
- Biswal, S., Kulas, J., Sun, H., Goparaju, B., Westover, M. B., Bianchi, M. T., & Sun, J. (2017). SLEEPNET: automated sleep staging system via deep learning. arXiv preprint arXiv:1707.08262. https://doi.org/10.48550/arXiv.1707.08262
- Obeid, I., & Picone, J. (2016). The temple university hospital EEG data corpus. Frontiers in neuroscience, 10, 196. https://doi.org/10.3389/fnins.2016.00196
- Koelstra, S., Muhl, C., Soleymani, M., Lee, J. S., Yazdani, A., Ebrahimi, T., ... & Patras, I. (2011). Deap: A database for emotion analysis; using physiological signals. IEEE transactions on affective computing, 3(1), 18-31.https://doi.org/10.1109/T-AFFC.2011.15
- Li, X., Zhao, Z., Song, D., Zhang, Y., Pan, J., Wu, L., ... & Wang, D. (2020). Latent Factor Decoding of Multi-Channel EEG for Emotion Recognition Through Autoencoder-Like Neural Networks. Frontiers in Neuroscience, 14, 87. https://doi.org/10.3389/fnins.2020.00087
- López-Larraz, E., Ibáñez, J., Trincado-Alonso, F., Monge-Pereira, E., Pons, J. L., & Montesano, L. (2018). Comparing recalibration strategies for electroencephalography-based decoders of movement intention in neurological patients with motor disability. International journal of neural systems, 28(07), 1750060. https://doi.org/10.1142/s0129065717500605
- Hartmann, K. G., Schirrmeister, R. T., & Ball, T. (2018). EEG-GAN: Generative adversarial networks for electroencephalograhic (EEG) brain signals. arXiv preprint arXiv:1806.01875. https://doi.org/10.48550/arXiv.1806.01875
Related resources
- All about EEG artifacts and filtering tools: Discover what EEG artifacts are, their most common causes, and how to identify or minimize them.
- EEG Synchronization With Other Biosensors (EEG, ECG, EMG, eye tracking, etc.), and Software: Understand what neural synchronization in EEG is and why it matters for studying brain connectivity.
- EEG and Virtual Reality: The Neuroadaptive Future of Neurotechnology: Learn about applications combining EEG and virtual reality in research and immersive experiences.
- What is QEEG Brain Mapping?: Learn what quantitative EEG (QEEG) is, how it's analyzed, and its clinical and research applications.
- EEG Electrode Placement Options: Learn how and where to position electrodes on the scalp for accurate and reliable EEG recordings.
- What is EEG and what is it used for?: A beginner-friendly introduction to EEG: how it works, its main applications in medicine and research, and the types of devices available.
- The Use of EEG for ADHD Diagnosis and Treatment: Discover how EEG is used to assess and understand ADHD from a neurophysiological perspective.
- What is BCI? An introduction to brain-computer interface using EEG signals: An introduction to the mechanisms of Brain-Computer Interfaces (BCI), detailing how they translate neural activity into computational commands.
- Sleep EEG for Diagnosis and Research: How EEG is used to study sleep stages, diagnose sleep disorders, and explore their impact on cognition and mental health.
